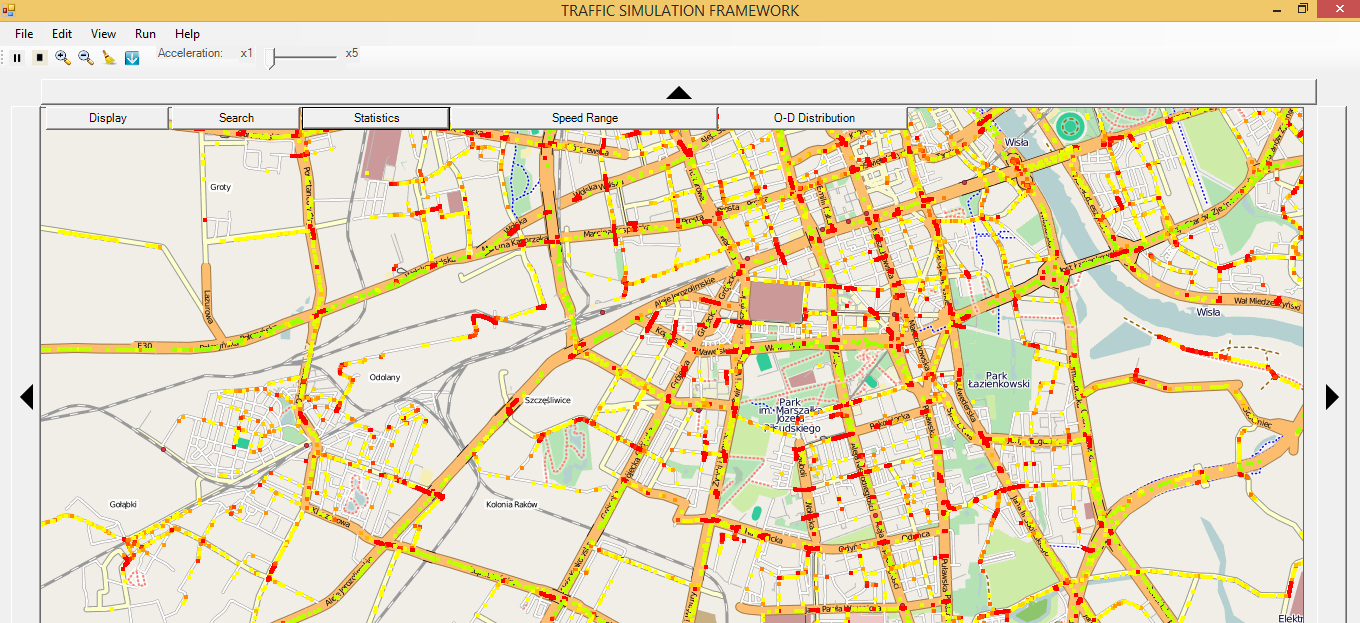
 W niniejszym artykule przedstawiam opracowany przeze mnie wieloagentowy, mikroskopowy model symulacji ruchu pojazdów w skali dużego miasta oraz jego zastosowania w dziedzinie ITS. Model zaimplementowałem w programie komputerowym Traffic Simulation Framework (TSF), wykonanym w technologii .NET, w języku C#. Program TSF znalazł dotychczas wiele zastosowań w zagadnieniach związanych z analizą, predykcją i optymalizacją ruchu drogowego w mieście. Z programu oraz wygenerowanych przez niego danych korzystali już w swoich badaniach naukowcy z Polski, ale również m.in. z Iranu, Japonii, Niemiec, USA.
W niniejszym artykule przedstawiam opracowany przeze mnie wieloagentowy, mikroskopowy model symulacji ruchu pojazdów w skali dużego miasta oraz jego zastosowania w dziedzinie ITS. Model zaimplementowałem w programie komputerowym Traffic Simulation Framework (TSF), wykonanym w technologii .NET, w języku C#. Program TSF znalazł dotychczas wiele zastosowań w zagadnieniach związanych z analizą, predykcją i optymalizacją ruchu drogowego w mieście. Z programu oraz wygenerowanych przez niego danych korzystali już w swoich badaniach naukowcy z Polski, ale również m.in. z Iranu, Japonii, Niemiec, USA.
Opracowany wieloagentowy model ruchu jest oparty na teorii probabilistycznych automatów komórkowych oraz popularnym modelu ruchu pojazdów na prostych odcinkach drogi – modelu Nagela-Schreckenberga (model Na-Sch), ale istotnie ten model rozszerza. Został skonstruowany tak, by opisywać w języku matematyki ruch pojazdów w realistycznych sieciach drogowych (takich jak np. sieć drogowa w Warszawie), reprezentowanych za pomocą grafów skierowanych. Reprezentacja sieci drogowej jest konstruowana na podstawie danych rzeczywistych pochodzących z serwisu OpenStreetMap. W szczególności, uwzględniane są różne typy dróg (rozróżniane wartościami domyślnych maksymalnych prędkości, różną liczbą pasów ruchu) oraz światła drogowe. Wierzchołki grafu reprezentującego sieć drogową są punktami, w których pojazdy mogą rozpoczynać i kończyć jazdę, zaś właściwy ruch odbywa się na krawędziach grafu, które są reprezentowane jako taśmy o określonej długości (pasy ruchu), podzielone na komórki, tworząc w ten sposób automat komórkowy. Ruch w modelu odbywa się w czasie dyskretnym, w każdym kroku ewolucji automatu komórkowego każda komórka może być pusta lub zajęta przez maksymalnie 1 pojazd, a każdy pojazd ma obliczany stan (prędkość i położenie) zgodnie z określonymi regułami, inspirowanymi oryginalnym modelem Nagela-Schreckenberga. Istotnym rozszerzeniem oryginalnego modelu jest redukcja prędkości przed skrzyżowaniem i przed światłami, możliwość zmiany pasa jazdy, niecałkowite wartości prędkości, położenie w obrębie pojedynczej komórki. Ponadto, pojazdy są rozróżnialne, każdy z nich posiada określoną trasę przejazdu (ciąg wierzchołków prowadzących od wierzchołka startowego do wierzchołka końcowego w grafie sieci drogowej), rozpoczyna ruch o określonej porze (czas od rozpoczęcia ewolucji modelu) i posiada atrybut określający „agresywność” kierowcy (parametr losowany z rozkładu normalnego), wpływający na maksymalną prędkość jazdy na odcinkach danego typu. Położenia początkowe i końcowe wyznaczane są z rozkładów punktów startowych i końcowych (odpowiednik macierzy podróży) – mapa sieci drogowej podzielona jest na rejony (w przypadku Warszawy jest ich 400), na których określone są rozkłady prawdopodobieństwa, odpowiadające szansom na wylosowanie punktów z danego obszaru jako punktów startowych lub końcowych, w zależności od rozkładu. Wszystkie wierzchołki z danego rejonu mają już jednakowe prawdopodobieństwa wylosowania (rozkład jednostajny), dzięki czemu można łatwo wybrać punkty startowe i końcowe dla pojazdów.
Opisany model został zaimplementowany w programie komputerowym Traffic Simulation Framework (TSF). Program posiada intuicyjny graficzny interfejs użytkownika (GUI), umożliwia przeprowadzanie wydajnych symulacji z udziałem dużej liczby pojazdów (kilkaset tysięcy) w czasie rzeczywistym lub szybciej (na standardowym sprzęcie komputerowym). Domyślne rozkłady w programie TSF zostały skonstruowane za pomocą danych rzeczywistych, np. danych na temat miejsc zamieszkania/gęstości zaludnienia poszczególnych rejonów (dane z GUS) oraz danych pomiarowych pochodzących z badań ruchu w Warszawie (natężenia ruchu na określonych krawędziach). Po wybraniu punktów startowych i końcowych trasa przejazdu obliczana jest za pomocą algorytmu A*, w którym każda krawędź grafu ma wagę odpowiadającą oczekiwanemu czasowi przejazdu tą krawędzią, a heurystyka jest wyznaczana na podstawie odległości geograficznej między 2 wierzchołkami w grafie. Z poziomu GUI można edytować wiele parametrów symulacji (liczba pojazdów, rozkłady punktów startowych i końcowych, konfiguracje sygnalizacji świetlnych, monitorowane obszary), a program może wypisywać w trakcie symulacji kilka typów danych. Funkcjonalności te znalazły już zastosowanie w kolejnych badaniach.
Pierwszym istotnym zastosowaniem programu TSF było przygotowanie danych do konkursu dotyczącego predykcji ruchu drogowego „TomTom Traffic Prediction for Intelligent GPS Navigation” (http://tunedit.org/challenge/IEEE-ICDM-2010), organizowanego przy konferencji ICDM 2010, we współpracy z firmami TunedIT i TomTom (do tego celu przeprowadziłem łącznie kilka tysięcy godzin symulacji komputerowej – program TSF był uruchamiany z różnymi zestawami parametrów na wielu komputerach w laboratorium). Uczestnicy konkursu mieli za zadanie prognozowanie natężeń ruchu, średnich prędkości przejazdu i lokalizacji korków w pewnych obszarach Warszawy, w określonych godzinach. Konkurs zakończył się dużym sukcesem, zarejestrowało się w nim prawie 600 zespołów, uczestnicy opracowali wiele ciekawych algorytmów predykcji, autorzy najlepszych rozwiązań pochodzili z takich ośrodków badawczych jak Uniwersytet Warszawski, IBM Research, AT&T Labs.
Kolejnym zastosowaniem programu TSF są prowadzone przeze mnie prace badawcze dotyczące sterowania ruchem drogowym. Dalekosiężnym celem tych badań jest opracowanie inteligentnego (zdolnego do adaptowania się do istniejących warunków) systemu zarządzania ruchem w miastach. System taki mógłby gromadzić dane o rzeczywistym ruchu z sensorów zainstalowanych w mieście oraz w pojazdach, wykrywać na ich podstawie krytyczne sytuacje (np. wypadek, zablokowana droga) i właściwie na nie reagować (adaptować ustawienia sygnalizacji świetlnych, proponować alternatywne trasy przejazdu). Program TSF obecnie jest używany do obliczania funkcji oceny jakości konfiguracji sygnalizacji świetlnych na skrzyżowaniach w sieci drogowej Warszawy w celu znajdowania suboptymalnych konfiguracji. Problem ten (znany jako Traffic Signal Setting problem) jest bardzo trudny od strony obliczeniowej – dla jednej z jego prostszych wersji (przy deterministycznym modelu ruchu i upraszczających założeniach) udowodniono, że należy on do klasy problemów NP-hard, w której są problemy obliczeniowe uważane powszechnie za bardzo trudne. Konsekwencją jest to, że najprawdopodobniej nie istnieje algorytm, który mógłby rozwiązać ten problem szybko – w czasie, który w funkcji rozmiaru danych wejściowych dałoby się ograniczyć przez wielomian. W praktyce problemu nie da się więc rozwiązać w rozsądnym czasie dla dużych danych wejściowych (np. odpowiadających Warszawie), nawet na najpotężniejszych obecnie komputerach. Z uwagi na nieprzewidywalność rzeczywistego ruchu i niedeterminizm stosowanych modeli ruchu trudno jest nawet matematycznie zdefiniować „optymalność” konfiguracji sygnalizacji świetlnej. Dodatkowo, przestrzeń możliwych rozwiązań dla miasta takiego jak Warszawa jest olbrzymia: ok. 800 skrzyżowań ze światłami, maksymalna długość cyklu – 120 sekund, powoduje, że rozmiar tej przestrzeni jest rzędu 120800 przy założeniu całkowitoliczbowych (liczonych w sekundach) przesunięć w fazie (dla porównania: szacowana liczba atomów w obserwowalnym Wszechświecie to 1080)..Zamiast szukać rozwiązań optymalnych, które trudno zdefiniować i trudno w tak dużej przestrzeni znaleźć, można jednak znajdować rozwiązania suboptymalne – potencjalnie trochę gorsze od tych (nieznanych) najlepszych, ale akceptowalne (np.: powodujące, że na pewno lub z bardzo dużym prawdopodobieństwem nie będą tworzyć się zatory) i możliwe do znalezienia w rozsądnym czasie. Im więcej czasu można będzie poświęcić na przeszukiwanie przestrzeni rozwiązań, tym lepsze rozwiązanie suboptymalne można będzie potencjalnie znaleźć. Trzeba jednak odpowiednio przestrzeń rozwiązań zamodelować i przeszukiwać, aby te akceptowalne rozwiązania znaleźć.
Do rozwiązania tego problemu stosuję obecnie m.in. algorytm genetyczny, inspirowany procesem doboru naturalnego. Wstępne eksperymenty z użyciem opracowanego modelu mikroskopowego w programie TSF pokazały, że można dzięki takiemu podejściu otrzymać kilkuprocentową poprawę badanych funkcji oceny (np. czasów czekania i czasów przejazdu z małą prędkością). Duża złożoność obliczeniowa proponowanego rozwiązania spowodowała, że konieczne stało się usprawnienie projektowanych rozwiązań, zarówno od strony koncepcyjnej, jak i sprzętowej. W obecnych badaniach rozważam m.in. znajdowanie lokalnie suboptymalnych konfiguracji świateł i łączenie ich w rozwiązanie globalne (analogia do metody „divide-and-conquer”, znanej w informatyce), wprowadzanie więzów ograniczających przestrzeń przeszukiwań (np. „zielona fala”), zastosowanie mezoskopowego modelu ruchu (zamiast mikroskopowego), stosowanie obliczeń w klastrze o dużej mocy obliczeniowej. Najnowsze obliczenia przeprowadzone na klastrze HP Blade System na Uniwersytecie Rzeszowskim pokazały, że zastosowanie modelu mezoskopowego (w którym czasy przejazdu są jedynie szacowane, a nie obliczane za pomocą mikroskopowej symulacji) daje ponad 100-krotne przyspieszenie obliczeń, możliwe jest również znalezienie konfiguracji sygnalizacji świetlnych zmniejszających o 10-15% (w porównaniu do znanych, bazowych konfiguracji) łączne czasy czekania przed skrzyżowaniem. Złożoność obliczeniowa proponowanych rozwiązań jest wciąż zbyt duża, aby dało się je zastosować do sterowania ruchem w czasie rzeczywistym (a więc: z maksymalnie kilkusekundowym czasem reakcji na rzeczywiste warunki na drodze), ale możliwe byłoby już obliczanie domyślnych, dobrych globalnie konfiguracji sygnalizacji świetlnych raz na 30-60 minut, a potem lokalne ich adaptowanie do zmieniającej się sytuacji. Przewiduję jednak, że dzięki zastosowaniu obliczeń funkcji oceny jakości konfiguracji sygnalizacji świateł w klastrze obliczeniowym, z wykorzystaniem wielu procesorów i rdzeni obliczeniowych, będzie potencjalnie możliwe znajdowanie takich suboptymalnych konfiguracji znacznie szybciej niż obecnie, w czasie maksymalnie kilku sekund. Może to jednak wymagać mocy obliczeniowej znacznie większej niż obecnie (wstępne szacunki pokazują, że w przypadku sterowania ruchem w Warszawie może być do tego potrzebny sprzęt o mocy zbliżonej do najpotężniejszego obecnie w Polsce komputera Prometeusz), mogą być też potrzebne zaawansowane metody przetwarzania dużych zbiorów danych w klastrach, np. oparte na modelu MapReduce opracowanym w firmie Google. Równolegle warto więc badać alternatywne podejścia, w których sterowanie sygnalizacjami świetlnymi odbywa się nie w scentralizowanym modelu, ale w modelu rozproszonym, w którym kontrolery sygnalizacji świetlnych mogłyby się lokalnie komunikować, wymieniać informacjami o liczbie pojazdów, długości kolejek, czasie czekania, a następnie samoorganizować się na niedużym obszarze. Badania nad tego typu podejściem prowadzone są obecnie m.in. w Toronto. Może się okazać, że najefektywniejszą metodą sterowania sygnalizacjami świetlnymi będzie podejście hybrydowe, łączące wspomniane podejście scentralizowane (do znajdowania globalnych ustawień przesunięć w fazie i długości poszczególnych faz) z podejściem rozproszonym (adaptowanie długości poszczególnych faz w czasie rzeczywistym). Najpopularniejsze i wdrażane wciąż na świecie rozwiązania do sterowania światłami (np. SCATS, SCOOT) zostały opracowane już wiele lat temu, są bardzo dobre i poprawiają parametry ruchu w miastach, ale nie są doskonałe i nie korzystają z najnowszych osiągnięć techniki, wciąż są możliwości istotnego usprawnienia wdrażanych w wielu miastach rozwiązań. Projektowane przeze mnie metody są w porównaniu do nich bardzo innowacyjne.
Jednym z warunków istotnej poprawy istniejących rozwiązań zarządzania ruchem jest jednak dobra znajomość sytuacji w ruchu drogowym, a więc aktualnych położeń i prędkości pojazdów, a także ich przewidywanych tras przejazdu, aby można było robić dokładne krótkoterminowe predykcje ruchu. Obecnie jest dostępna jedynie szczątkowa wiedza na ten temat, dane tego typu mogą pochodzić m.in. z urządzeń mobilnych z nawigacją GPS. W przyszłości, gdy większość pojazdów będzie wyposażona w komputery pokładowe (np. sterujące ruchem, jak w przypadku pojazdów autonomicznych) z dostępem do informacji o położeniu pojazdu (pochodzących np. z danych z nawigacji satelitarnej lub dzięki innym metodom pozycjonowania), zbieranie tego typu zanonimizowanych danych i przesyłanie ich w trybie „online” do systemu zarządzania ruchem (tzw. komunikacja V2I) może być już standardem. Powinna być to znacznie prostsza i tańsza metoda detekcji pojazdów niż stosowane obecnie metody (np. pętle indukcyjne, wideodetekcja), sprowadzająca się do zainstalowania odpowiedniego programu na urządzeniu mobilnym lub komputerze pokładowym w pojeździe oraz przesyłania danych do systemu zarządzania ruchem. Program taki mógłby mieć przy okazji wiele innych zastosowań, m.in. nawigacja, informowanie podróżnych o sytuacji na drodze, znajdowanie i rezerwowanie miejsca parkingowego, podpowiadanie co można zwiedzić po drodze lub w pobliżu miejsca docelowego, automatyczne wykrywanie wypadku i natychmiastowe informowanie odpowiednich służb.
Kolejnym zastosowaniem symulatora TSF jest pozyskiwanie wiedzy na temat ruchu drogowego poprzez interakcję (dialog) programu TSF z ekspertami oceniającymi obserwowany, symulowany programem TSF ruch w pobliżu dużego skrzyżowania (badania w tym zakresie prowadzę wspólnie z dr. Piotrem Wasilewskim z Wydziału Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego). W tym celu opracowana została specjalna wersja programu TSF, która służy do prezentacji różnych sytuacji (rozróżnianych liczbą pojazdów, rozkładami punktów startowych i końcowych) na wybranym skrzyżowaniu w Warszawie. Zadaniem ekspertów jest z kolei ocena natężenia obserwowanego ruchu i uzasadnienie swojej oceny (w pierwszym eksperymencie były to uzasadnienia wyrażane w języku naturalnym, w drugim – eksperci wybierali gotowe uzasadnienia, przygotowane po analizie wyników pierwszego eksperymentu). Pozyskana w ten sposób wiedza posłuży do konstrukcji algorytmów uczenia maszynowego – hierarchii klasyfikatorów aproksymujących nieostre, czasowo-przestrzenne, wysokopoziomowe pojęcia dotyczące ruchu drogowego (np. „duże natężenie ruchu”) z danych niskopoziomowych, sensorowych (np. położenia i prędkości pojazdów). Dalekosiężnym celem jest opracowanie programów komputerowych, które będą potrafiły „rozumować” o ruchu drogowym w podobny sposób jak to robi człowiek, dzięki czemu będą mogły m.in. wspierać ludzi w procesach decyzyjnych związanych z inżynierią ruchu drogowego. Możliwe będzie również przekazywanie uczestnikom ruchu przystępnych informacji o faktycznym stanie ruchu drogowego tak, aby rozumieli przekazywaną informację w sposób, w jaki powinni ją rozumieć, oraz aby mogli podejmować właściwe decyzje dotyczące swojej podróży (np. wybór odpowiedniej trasy przejazdu).
Program Traffic Simulation Framework jest cały czas rozwijany i znajduje wiele zastosowań w dziedzinie Inteligentnych Systemów Transportowych (ITS). Są plany, aby w przyszłości był on „sercem” Krajowego Centrum Kompetencji ITS, umożliwiając prowadzenie wielu ciekawych prac badawczych.
O autorze:
 Paweł Gora jest doktorantem informatyki na Wydziale Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego, na tym Wydziale ukończył też studia magisterskie z matematyki oraz informatyki, jego opiekunem naukowym jest prof. dr hab. Andrzej Skowron. W pracy naukowej zajmuje się m.in. zagadnieniami związanymi z modelowaniem, analizą, predykcją i optymalizacją ruchu pojazdów w mieście. Opracował zaawansowany program do symulacji ruchu pojazdów w mieście, Traffic Simulation Framework, z którego korzystali już naukowcy z wielu krajów, a obecnie pracuje nad nowoczesnymi, adaptacyjnymi algorytmami zarządzania ruchem pojazdów w mieście (w tym – ruchem pojazdów autonomicznych), wykorzystującymi zaawansowane narzędzia sztucznej inteligencji, uczenia maszynowego, analizy danych, a także dane z systemów nawigacji satelitarnej i narzędzia do komunikacji pojazdów z otoczeniem i z innymi uczestnikami ruchu (komunikacja V2X). Jest autorem prac naukowych, które były już wielokrotnie cytowane. Wyniki swoich badań prezentował już podczas wielu konferencji i spotkań, m.in. na University of Cambridge, w ETH Zurich, Google Zurich (Tech Talk), Massachusetts Institute of Technology, University of Toronto. Za swoją pracę badawczą otrzymał prestiżowe stypendia i nagrody, np. “Doktoraty dla Mazowsza”, “Nowoczesny Uniwersytet”, nagrodę “LIDER ITS 2015” za najlepszą pracę badawczo-rozwojową w dziedzinie Inteligentnych Systemów Transportowych. Poza pracą naukową angażował się również w działalność dydaktyczną, społeczną i organizacyjną, m.in. przez 3 lata był Przewodniczącym Wydziałowej Rady Doktorantów MIMUW, od 4 jest członkiem Rady Wydziału MIMUW, działał w komisjach stypendialnych, Wydziałowym Zespole Zapewniania Jakości Kształcenia, a także jako Microsoft Student Partner (m.in. reaktywował Grupę .NET na Uniwersytecie Warszawskim), prowadził zajęcia dydaktyczne z Programowania Obiektowego i Systemów Uczących Się. Pracował w 5 projektach naukowych realizowanych na UW, odbywał też staże programistyczne i badawcze w Microsoft, Google, CERN i IBM Research.
Paweł Gora jest doktorantem informatyki na Wydziale Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego, na tym Wydziale ukończył też studia magisterskie z matematyki oraz informatyki, jego opiekunem naukowym jest prof. dr hab. Andrzej Skowron. W pracy naukowej zajmuje się m.in. zagadnieniami związanymi z modelowaniem, analizą, predykcją i optymalizacją ruchu pojazdów w mieście. Opracował zaawansowany program do symulacji ruchu pojazdów w mieście, Traffic Simulation Framework, z którego korzystali już naukowcy z wielu krajów, a obecnie pracuje nad nowoczesnymi, adaptacyjnymi algorytmami zarządzania ruchem pojazdów w mieście (w tym – ruchem pojazdów autonomicznych), wykorzystującymi zaawansowane narzędzia sztucznej inteligencji, uczenia maszynowego, analizy danych, a także dane z systemów nawigacji satelitarnej i narzędzia do komunikacji pojazdów z otoczeniem i z innymi uczestnikami ruchu (komunikacja V2X). Jest autorem prac naukowych, które były już wielokrotnie cytowane. Wyniki swoich badań prezentował już podczas wielu konferencji i spotkań, m.in. na University of Cambridge, w ETH Zurich, Google Zurich (Tech Talk), Massachusetts Institute of Technology, University of Toronto. Za swoją pracę badawczą otrzymał prestiżowe stypendia i nagrody, np. “Doktoraty dla Mazowsza”, “Nowoczesny Uniwersytet”, nagrodę “LIDER ITS 2015” za najlepszą pracę badawczo-rozwojową w dziedzinie Inteligentnych Systemów Transportowych. Poza pracą naukową angażował się również w działalność dydaktyczną, społeczną i organizacyjną, m.in. przez 3 lata był Przewodniczącym Wydziałowej Rady Doktorantów MIMUW, od 4 jest członkiem Rady Wydziału MIMUW, działał w komisjach stypendialnych, Wydziałowym Zespole Zapewniania Jakości Kształcenia, a także jako Microsoft Student Partner (m.in. reaktywował Grupę .NET na Uniwersytecie Warszawskim), prowadził zajęcia dydaktyczne z Programowania Obiektowego i Systemów Uczących Się. Pracował w 5 projektach naukowych realizowanych na UW, odbywał też staże programistyczne i badawcze w Microsoft, Google, CERN i IBM Research.
Strona wydziałowa: http://www.mimuw.edu.pl/~pawelg
Profil Google Scholar: http://scholar.google.com/citations?user=GbZr2MQAAAAJ
Screencast programu Traffic Simulation Framework, którego Paweł Gora jest autorem: www.mimuw.edu.pl/~pawelg/screen.wmv

